Algorithm expert Zhao Jinglei: The road to computer vision
Lei Fengnet Note: Author Zhao Jinglei, the CEO of Reading Technology, Dr. Artificial Intelligence of Shanghai Jiaotong University, former head of Alibaba Beijing Algorithm Research Center, focusing on artificial intelligence algorithm research for more than 15 years. This article is Lei Feng network exclusive article.

2016 is the 60th anniversary of the development of artificial intelligence, artificial intelligence has come a long way, with the emergence of AlphaGo's brilliant record, once again detonated the development of artificial intelligence in various fields. Recalling the road to the development of computer vision can enable us to step on the accumulation of history, follow the tide of development, and explore the future.
First, the cognitive basis of computer visionThe human understanding of the world is very simple. We can see at a glance whether a fruit is an apple or an orange. But for the machine, how do we write a program for the machine to distinguish between apples and oranges?

(Human identification)
If you let everyone think, we will give a variety of answers, such as whether or not to allow the machine to distinguish between the color of the fruit, or through the shape and texture to distinguish and so on.

(based on color, shape, texture recognition)
Before the advent of deep learning, this was based on finding the right features to allow the machine to identify the state of the item, which basically represented all of computer vision.
Taking color features as an example, it is a feature that is still widely used today. We call it the color histogram feature. It is the simplest and most intuitive way to digitally express the colors of actual pictures. Machine recognition pictures can only be represented by two-dimensional vectors. We all know that the color value can be represented by the RGB primary colors. The horizontal axis of the color histogram represents the RGB value of the color, indicating the possibility of all the colors of an item, and the vertical axis represents the number of pixels of the entire image with a certain color value. In fact, with such a very intuitive method, the machine can perform color representation of the pictures it sees. In the past twenty or thirty years, there have been many explorations and researches on the representation of color features, such as: Variants of various color histograms, allowing computers to better represent the color of images by using two-dimensional numerical strings. The features make it possible to distinguish the different items seen.
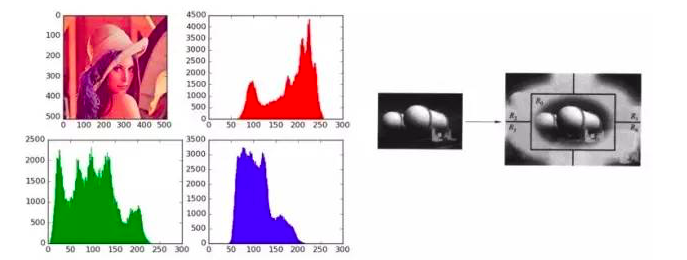
Left: (color histogram striker 1995) Right: (color distance striker 1995)
Taking the texture feature as an example, the orange will have a pitted texture, while the apple's texture is very smooth. This kind of local texture depiction, how to abstractly express it in the form of digital strings, is the same as the color features. This is the problem that computer vision has been seeking and optimizing for many years. The following figure is an example of the representation of texture features used in various fields in computer vision.

(Texture Histogram)

(SDM)
The same is true for the shape features. The following two figures can be intuitively illustrated by computer vision through shape features.

(Hog: Dalal, 2005)
From these examples, it can be seen that in the past many years of computer vision, the method of dealing with problems is very simple. It is to find a suitable feature abstraction method, and to characterize a problem to be identified or to be classified, and then perform the calculation process.
If you want to do face recognition, you need to find out whether the color feature or the texture feature or the shape feature is more suitable for expression. How can you separate the target problem? For people's faces, the effect of color is not great, because the color of the face is almost the same. However, the folds and textures of the face, the distance between the two eyes, etc. may represent the differences between different people, and may be more effective than textures and structural features. And if we want to detect and recognize the human body, texture features may not be so important, because people will wear a variety of clothes, but the shape characteristics will be very important. Therefore, computer vision in the past was to select different feature representation methods for different problems.
Second, the development of computer visionSince 2006, in the nearly 10 years, a fundamental change has taken place in the method of computer vision. The appearance of deep learning has changed our definition of computer vision to some extent. Let us first understand the course of the development of computer vision, and see what is the opportunity and accumulation, so that computer vision has undergone such changes.
The history of computer vision can be traced back to 1966, when the famous artificial intelligence expert Marvin Minsky laid out a very interesting summer job for his undergraduate students by letting students connect a camera in front of the computer and then write a The program lets the computer tell us what the camera sees. The master is a master. This is a real challenge. In a sense it represents all the things computer vision needs to do. Therefore, we think this is a starting point.
In the 1970s, researchers began to try to solve the problem of letting computers tell him exactly what they saw. Researchers think that to let the computer know what to see, it may be necessary to first understand how people understand the world. Because at that time there was a general perception that people understood the world because people had two eyes and the world he saw was three-dimensional. He could understand the world from this three-dimensional shape. Under this cognitive situation, researchers hope to recover the three-dimensional structure from the image first, and then to understand and judge it.
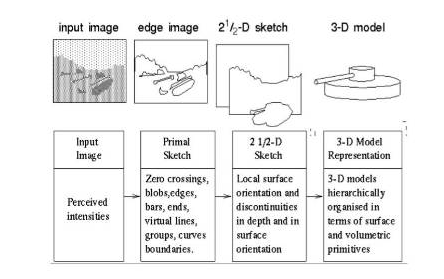
(David Marr, 1970s)
The 1980s was a very important stage in the development of artificial intelligence. The reasoning of logic and knowledge base in the artificial intelligence community is very popular. Researchers began to do a lot of expert reasoning systems. The computer vision methodology has also begun to make some changes at this stage. People find it necessary to let computers understand images without necessarily restoring the three-dimensional structure of objects. For example: Let the computer recognize an apple, assuming that the computer knows the shape or other features of the apple in advance, and establishes such an a priori knowledge base, then the computer can match such a priori knowledge with the object representation. If it can match, the computer recognizes or understands the object it sees. So, there were many methods in the 1980s, including geometric and algebraic methods, which transformed our known objects into some a priori representations that were then matched with the images of objects seen by computers .
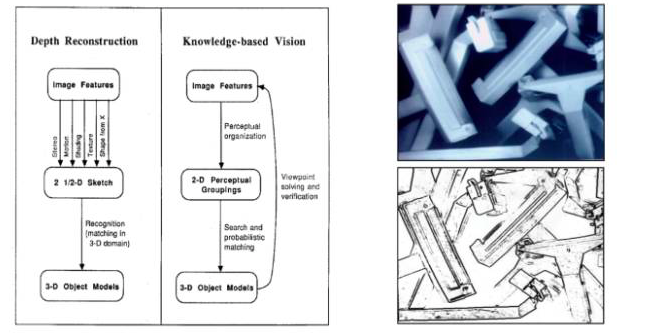
(David Lowe, 1987)
In the 90s of last century, a relatively big change in the artificial intelligence industry emerged. That is, the emergence and popularity of statistical methods. At this stage, it has experienced some relatively large development points, such as local features that are still widely used. The characterizations of the shapes, colors, and textures described above are actually influenced by the perspective. A person looks at an item from a different perspective, and its shape, color, and texture may not be the same. With the popularity of statistical methods in the 1990s, researchers have found a statistical tool that can characterize some of the most essential local features of an item. For example: To identify a truck, through shapes, colors, textures, may not be stable if passed Local features, even if the perspective changes, will accurately identify it. The development of local features actually led to the emergence of many later applications. For example: image search technology is really useful, but also due to the emergence of local features. Researchers can create a local feature index on the item and find similar items through local features. In fact, with such local points, matching can be more accurate.

(David Lowe, 1999)
By the year 2000 or so, machine learning methods began to prevail. It used to be through some rules, knowledge, or statistical models to identify what the image represents, but machine learning methods are completely different from before. Machine learning can automatically summarize the characteristics of an item from a large amount of data and then identify it. At such a time, the computer vision community has several very representative jobs, such as face recognition.
To identify a face, the first step is to extract the face area to be identified from the picture. This is called face detection. When you take a picture, you will see a small box on the camera flashing. This is actually the first step of face recognition, which is the detection of the face frame. In the past, this was a very difficult job, but around 2000, there was a very good algorithm that could quickly detect human faces based on machine learning, called the Viola & Jones face detector, which laid A foundation for contemporary computer vision.
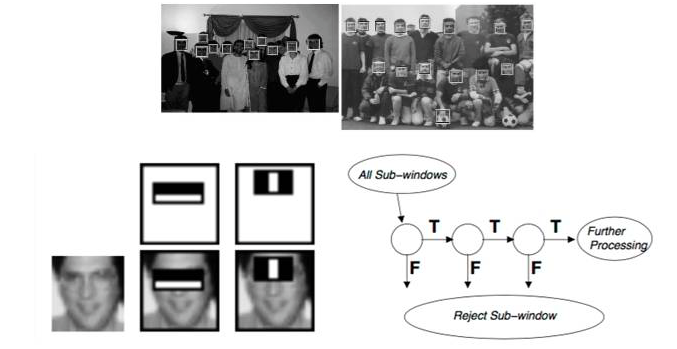
(Viola & Jones, 2001)
The prevalence of machine learning is actually accompanied by a necessary condition. In the year 2000 or so, the emergence and explosion of the entire Internet generated massive amounts of data, and large-scale data sets also accompany them. This is achieved through machine learning methods. Doing computer vision provides a good soil. During this period, there emerged a large number of academic and official data sets for different areas of evaluation. The most representative face detection is a data set called FDDB. This data set contains more than 5,000 face data. Each face is artificially framed. The machine can learn from any of these boxed data through some machine learning methods. Find the face area in the picture.
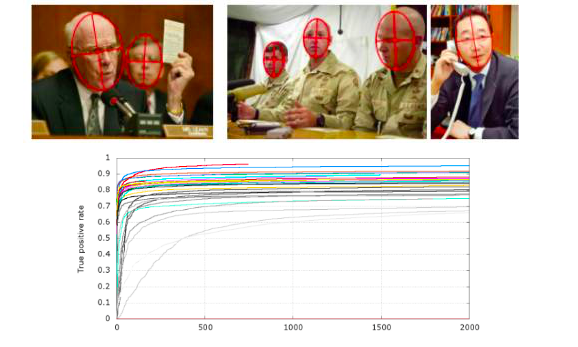
(FDDB, 5171 faces, 2845 images)
In addition, one of our familiar datasets is the face recognition dataset LFW. Referring to face recognition, we may have heard that "computers do more face recognition than people do." In fact, there are certain problems with this sentence. In many practical scenarios, 70% of face recognition personalities of computers may not reach. So under what circumstances is it more accurate than humans? One situation is on the LFW. The LFW dataset contains more than 10,000 faces and more than 5,000 data. Each person has multiple faces of real scenes shot in different situations. Based on such a data set, researchers can evaluate the accuracy of face recognition. The face recognition field is developing very fast, especially after the rise of deep learning in recent years, this data set has become very popular. The recognition rate of people on the LFW is probably 97.75%, and the machine can already be 99.75% or even higher on the LFW.
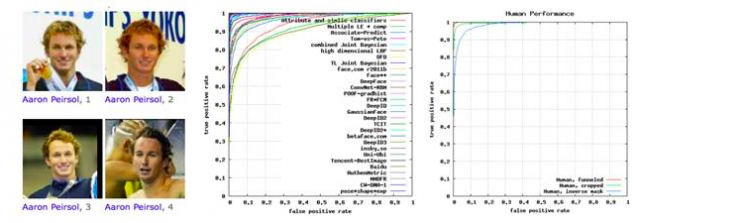
(13233 faces, 5749 people)
During this period, there were other very influential data sets, of which the most representative one was IMAGEMET, a project initiated by Professor Li Feifei. In a crowdsourcing manner, he labels 14 million pictures and divides them into more than 20,000 categories. These categories cover all things, such as animals, which may be divided into birds, fish, etc.; plants, which may be divided into trees And flowers. Her vision is ambitious, and she hopes to provide such a data set and provide a data soil for computer vision algorithms so that future machines can understand everything in the world.

In the 2000s, after artificial intelligence experienced a period of rapid development, the entire artificial intelligence has achieved very good applications in many industries. For example, there are search engines sorting and calculating advertisements outside the visual and so on. Visual field face detectors are also used. Used in a variety of cameras.
By the 2010's, artificial intelligence had entered one of the most exciting times. It was the era of deep learning. Deep learning has revolutionized the whole artificial intelligence in essence. In the last century, someone did a cat experiment. A hole was made in the cat's head, and various items were placed in front of the cat to observe the cat's reaction to different items. It has been found through experiments that when we place objects with very similar shapes, the same region of the cat's back cortex shows the same stimuli response. This experiment shows that the human visual system is cognitively stratified. After a multilayered neural network model simulating human brain cognition in the early stage experienced a low point around 2000, Professor Hinton published a training method for deep neural networks in Science in 2006, bringing with it the profound development of deep learning.
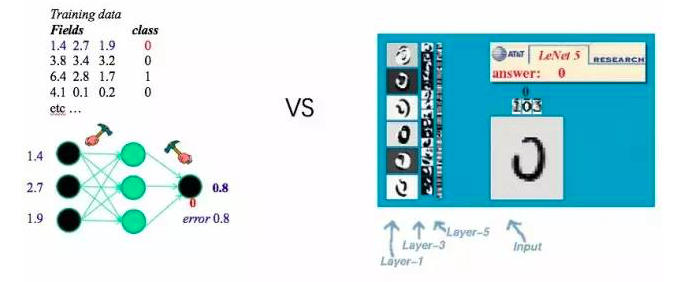
(LeNet-5, 1998)
The left side of the figure above is an ordinary three-layer neural network algorithm, which is a shallow learning method. In such a shallow neural network, the input data is still an artificially abstract feature, such as color, shape, texture, or local features. The right one is a deep learning method that is most commonly used now, convolutional neural networks. From the outside, the biggest change is that the input is the pixels of the original image. Instead of artificially expressing and abstracting features, the neural network itself is used to automatically perform feature abstraction in shallow layers. This is one of the fundamental differences between the shallow machine learning model and the deep learning model.

(Hinton, 2006)
 (Li, Tang etl, 2014-2015)
(Li, Tang etl, 2014-2015)
Since 2006, the entire computer vision industry has undergone qualitative changes in nearly 10 years. The emergence of deep learning has truly changed the definition of computer vision.
Third, the application of computer visionAfter the appearance of deep learning, the accuracy of various visual recognition tasks has been greatly improved. For facial expressions, before deep learning occurs, a common recognition algorithm, such as using colors, textures, shapes, or With local features, various features can be combined together, and the face recognition rate can only reach 94% to 95%. In many actual systems, such as previously used face attendance, the system may only be able to achieve 90% to 92% recognition rate. After deep learning emerged, this precision was directly increased to 99.5% and the error rate was reduced by 10 times.
This magnitude of error rate reduction is of great significance. For example: The accuracy of human body recognition is used in the assistive driving system of a car. If there is a missing report or wrong package, this is a very big thing. If it is 95% accurate, there are 100 people passing. Within a certain distance, he may have five misstatements or omissions. This is certainly unacceptable. However, if the accuracy is increased by a factor of 10 or 100, for example if 10,000 people have only 5 missed reports, then this may be feasible. Therefore, the appearance of deep learning makes some of the application areas where the visual method is not practical before. Basically, it is possible to obtain a good application through deep learning.
At present, the hot spots of computer vision are applied in some areas such as target detection, target recognition, target tracking, scene understanding, stereo vision, etc. Face recognition is more frequently used in the financial industry, such as face recognition authentication, etc.; image search is more intuitive. The application, such as taking a photo of a shoe and searching on Taobao, can find similar shoes. Another example is security, which is also a typical application field of computer vision; there is also a very large application, that is, in the field of robotics, including the entire smart device field, the emergence of deep learning makes the robot go in terms of visual ability or voice ability. It is possible to imitate human capabilities.
With the development of deep learning, there have also been some visual companies focusing on deep learning, such as Face++ and SenseTime focusing on financial and security monitoring, Tupu Technology focusing on image review, and clothing+ focusing on image search. Our reading technology focuses on embedded vision and machine vision.
Fourth, my explorationRecalling the development of computer vision, many companies have followed the trend of deep learning, including our reading.
The emergence of deep learning has led to many opportunities for entrepreneurship and innovation in the application of artificial intelligence.
For example, in the combination with the vertical industry, such as finance, medical industry, the application of this feature is that the calculation occurs on the server or cloud.
On the other hand, opportunities arise from the intelligent upgrade of various hardware devices . The application of this aspect is characterized by front-end and real-time computing. We all know that the previous smart hardware was not smart and the user experience was not good. The development of artificial intelligence algorithms will make a series of hardware devices become smart and become truly intelligent machines.
Embedded vision is to help a variety of smart machines, through embedded visual algorithms, so that it has a pair of human-like eyes to be able to recognize the surrounding people or scenes. This research applies to robots, smart homes, and automotive applications. Equipment and other fields mainly address the two major problems of human-computer interaction and scene perception. These two capabilities are the core capabilities that smart machines must have in the future. This is what we are doing.
Taking the smart machine as an example, it needs to understand people, know who the person is, and understand human expression changes and interactive gestures and human actions. This is actually the human-computer interaction layer. The scene perception layer of the intelligent machine is to put the intelligent machine in an unfamiliar environment, let it know what kind of environment it is in, enable it to identify items and scenes, be capable of autonomous navigation and positioning, and can walk freely. Computer vision is the future of human-computer interaction and scene perception.
How to provide smart machines with visual and cognitive solutions? Take us as an example -
First, the core algorithm engine is built on the bottom layer, such as face recognition, gesture recognition, human body recognition, and scene recognition. Secondly, at the algorithm level, we did two things: on one hand, we did hardware modules and on the other hand we did chips. All hardware layer efforts are to allow the underlying neural network deep learning algorithm to run fast and low power consumption on embedded devices. Through the solution of hardware and software integration, we hope to help the future intelligent machines to easily access visual cognition services to recognize the world.
V. Looking at the Future Challenges from the Development of Deep LearningThe development of computer vision certainly can't be plain sailing.
For any visual recognition task, changes in its natural conditions, such as changes in posture, occlusion, lighting, and other conditions, will greatly affect its recognition accuracy and accuracy. How to solve this problem is actually the biggest challenge facing the entire computer vision.
Deep learning is good at classification problems, but it is not very good at understanding contextual semantics. For example, let it understand what human beings say. The application in this area has not made much substantive progress in recent years. This is one of the reasons why I focused on computer vision. If I do a natural language understanding, deep learning is currently Little help, but the understanding of continuous semantics and context is the focus of deep learning model research in recent years. I believe there will be breakthroughs in the future.
Deep learning has indeed brought about a substantial breakthrough, but for many tasks, there is still a small gap from the accuracy that we really want to achieve. For example, the accuracy of human detection and item identification is comparable to ours in real scenes. Not enough. The entire academic community has continued to study the new generation of deep learning models. For example, when people understand the world, it not only passes information from the primary cortex of the brain to deep neurons. As people understand, psychologists have discovered that deep neurons in the human brain can in turn guide the cognition of the initial input layer. Therefore, I believe that deep learning will bring about greater breakthroughs in theoretical models over the years, and this breakthrough may make this model more and more close to our people's handling of information.
The road of computer vision, the road is long, its repair far, I will search and search.
Lei Feng Network (Search "Lei Feng Network" public number concerned) Note: Reprinted please contact us to authorize, and retain the source and author, may not delete the content.
Multi Style Portable Wallet,Portable Wallet,Large Capacity Zero Wallet,Fashion Zero Wallet
Dongguan City Diadia Industry Co.,Ltd , https://www.diadiabag.com